You can easily nest functions in Python. That is, you define a function inside another function. This leads to a significant challenge, though: how can a nested function access variables of the surrounding function, when the surrounding function might already have died? Somehow, a function needs to capture all necessary variables it needs to properly execute: the function needs to close all open references. In this article, I want to explore how this works.
Disclaimer: I omitted some of the usually necessary checks and error handling in the following code, so as to concentrate on the aspects that are important for the article. But be aware that you should, at the very least, add a test like i < len(text) if you want to use this code.
Nested Functions
Wherein functions contain functions, not unlike a Matryoshka doll.
Every once in a while, I want to read individual tokens from an input text. The tokens might be numbers, identifiers, or symbols, but let’s concentrate on identifiers for the moment. Thus I have the following task: I have a string together with a starting position, and I need to extract an identifier, which might comprise lowercase and uppercase letters, digits, or the underscore character. Here is a function read_identifier that solves this task:
def read_identifier(text, start):
i = start
if not '0' <= text[i] <= '9':
while '0' <= text[i] <= '9' or 'A' <= text[i] <= 'Z' or 'a' <= text[i] <= 'z' or text[i] == '_':
i += 1
return text[start:i]This function does a nice job, but there is something I do not particularly like about it: the condition of the while-loop is way too long! I would make the case that such long chains of conditions hamper readability. What I rather do in such a situation is to create a new test-function, is_letter in this case. On first glance, the code gets longer, indeed, but in my humble opinion, the next version is much more readable. And, there is another huge bonus here: it becomes immediately apparent that the test depends only and solely on the “current” character in the input. You do not have to look twice to make sure that there isn’t something like a text[i+1] hidden somewhere in the test.
def read_identifier(text, start):
def is_digit(c):
return '0' <= c <= '9'
def is_letter(c):
return 'A' <= c <= 'Z' or 'a' <= c <= 'z' or c == '_'
i = start
if not is_digit(text[i]):
while is_letter(text[i]) or is_digit(text[i]):
i += 1
return text[start:i]When you look at this code, however, you will notice that I have put the functions is_digit and is_letter inside the function read_identifier. I nested the functions. This nesting has the effect that the two functions is_digit and is_letter are really private to read_identifier. In other words: I can do the refactoring of putting the tests into dedicated functions locally, without affecting any other code in the program (of course, if you find that you have several private is_letter-functions, it is time to think about putting them in global namespace).
Nested functions come with a nice benefit: they can access the local variables of the surrounding function. Perhaps, we sometimes want to allow an identifier to also contain dollar signs. We control this by a parameter (which, technically, is just a local variable in Python). The is_letter-function can directly access this flag, quite similar to how a function can access global variables from the surrounding module.
def read_identifier(text, start, dollar_is_letter=False):
def is_digit(c):
return '0' <= c <= '9'
def is_letter(c):
return 'A' <= c <= 'Z' or 'a' <= c <= 'z' or \
c == '_' or (c == '$' and dollar_is_letter)
i = start
if not is_digit(text[i]):
while is_letter(text[i]) or is_digit(text[i]):
i += 1
return text[start:i]If you were wondering about optimisation (which this article is not about, though): the refactoring presented here has no clear effect on performance. It neither slows down, nor speeds up the execution of read_identifier, it just makes it more readable. At first, it seems like we have added another function call, which should slow down execution. However, bear in mind that an “array” access like text[i] is in Python a function call, too, so that the refactoring can reduce the total number of calls.
If you really want to speed up the code, think, for instance, about reordering the test. If most of your identifiers comprise just lowercase letters, it might be a good idea to start with the 'a' <= c <= 'z', as all the remaining tests are then mostly obsolete, and not executed at all. In the end, this is a beautiful example of how optimisation is always a trade-off. As soon as you reorder the tests to make it go faster for lowercase letters, it will go slower for everything else. And if all character are equally likely, there is not much you can do, anyway.
Function Factories
Wherein functions give their children away.
The whole point of nesting in the example above was that the nested functions were totally private, and visible only within the surrounding function. Our next move is to violate this privacy principle, and expose the nested, private functions to others. We do this by returning one of our private functions.
While scanning our input file, and reading the tokens, I want to support not only decimal, but also hexadecimal numbers. Moreover, even the definition of what characters an identifier can comprise change. I will keep it simple here, and just differentiate between Python identifiers, as opposed to Lisp identifiers. The latter can also contain hyphens and question marks (in reality, there is more, of course).
So, what do I do? I have a function make_is_digit(base), which contains two nested versions of an is_digit-function. When make_is_digit is called, it returns either the decimal, or the hexadecimal version of is_digit. If this is new to you, then observe very closely: dec_is_digit, and hex_is_digit on lines 9 and 11, respectively, have no parentheses following. We are not calling these functions, but returning the functions themselves.
def make_is_digit(base):
def dec_is_digit(c):
return '0' <= c <= '9'
def hex_is_digit(c):
return '0' <= c <= '9' or 'A' <= c <= 'F' or 'a' <= c <= 'f'
if base == 10:
return dec_is_digit
elif base == 16:
return hex_is_digit We do the same for is_letter, which returns either the (Pseudo-)”Lisp” version, or the Python version of is_letter. Finally, in read_identifier, we decide that we want to use decimal digits, and Python’s character set for identifiers. Feel free to add other “languages” as you see fit.
def make_is_letter(language):
def lisp_is_letter(c):
return 'A' <= c <= 'Z' or 'a' <= c <= 'z' or c in ('_', '-', '?')
def python_is_letter(c):
return 'A' <= c <= 'Z' or 'a' <= c <= 'z' or c == '_'
if language == 'lisp':
return lisp_is_letter
elif language == 'python':
return python_is_letter
def read_identifier(text, start):
is_digit = make_is_digit(10)
is_letter = make_is_letter('python')
i = start
if not is_digit(text[i]):
while is_digit(text[i]) or is_letter(text[i]):
i += 1
return text[start:i]On the downside, is_letter can no longer access a flag dollar_is_letter as before, of course. Technically, the is_letter function “belongs” to make_is_letter now, and not to read_identifier. In a way, read_identifier just borrows a copy of python_is_letter and calls it is_letter.
There is a crucial point to be made here: each time make_is_letter is called, Python creates two new local functions lisp_is_letter, and python_is_letter, and then returns one of these. Using is (or the builtin function id()), you can directly see this:
is_letter_A = make_is_letter('python')
is_letter_B = make_is_letter('python')
print(is_letter_A is is_letter_B)Python’s output here will be a False – the two is_letter functions are not identical, even though they do the exact same thing, and refer to the same piece of code. In fact, the underlying code of the functions is identical, i. e. Python returns True here:
print(is_letter_A.__code__ is is_letter_B.__code__)Returning a new function is similar to how the following function returns a new list each time it is called. Just think about how you might modify the list afterwards, say, by appending another number. The next time you call make_list(), however, you still would want to get a fresh list [1, 2, 3] without the prior modifications.
def make_list():
return [1, 2, 3]Capturing The Environment
Wherein a function remembers its origins.
Why stop with the make_is_letter(language)? Let’s get crazy, and forget about languages. Actually, I don’t care about Lisp or Python at this point. I just want to get a suitable, and adaptable is_letter function.
I think, we can agree that the latin letters A through Z shall always be accepted as part of an identifier. What changes is just the set of special characters: {'_'} in the case of Python, {'_', '-', '?'} in the case of our toy-Lisp. And with this, our make_is_letter function becomes much more flexible than ever before. We give it a set of special characters we want to allow. It then creates a new is_letter function, which permits exactly the given set of special characters. The key point here is that this works exactly because Python creates a new and shiny version of private functions, each time make_is_letter is called.
def make_is_letter(special_chars: set):
def is_letter(c):
return 'A' <= c <= 'Z' or 'a' <= c <= 'z' or c in special_chars
return is_letter
def read_identifier(text, start):
is_letter = make_is_letter({'_', '$'})
i = start
if not is_digit(text[i]):
while is_digit(text[i]) or is_letter(text[i]):
i += 1
return text[start:i]This works without any issues, but there is a conceptual problem here! Recall that a function’s local scope is only temporary. This is an obnoxious way to say that the locals() dictionary of local variables exists only while the function is being executed. In other words, when you call make_is_letter(), the Python interpreter creates a new local namespace for all the local variables (including parameters). As soon as the function has run its course and returns, the interpreter throws away the local namespace.
Do you see the problem? At the time we actually call is_letter() inside read_identifier(), the parent function make_is_letter() has long finished, and all the local variables – including special_chars (!) – are gone. This, in turn, means that is_letter can no longer access the special_chars variable of its surrounding scope. And yet, it does just that.
Solving the Problem Manually
Functions are More than Just Code.
Let us assume for a moment that Python really does away with the local namespace of make_is_letter(), and thereby special_chars does become inaccessible. How would you save the day? How could we still make the special characters accessible to is_letter()?
The answer lies with default arguments. We make our is_letter function as before, but this time, we add another argument specials to it, and give the special_chars as a default argument:
def make_is_letter(special_chars: set):
def is_letter(c, specials=special_chars):
return 'A' <= c <= 'Z' or 'a' <= c <= 'z' or c in specials
return is_letterWhy does this work? Because default arguments are evaluated at the very moment def creates a new function (you may have painfully made that discovery when you tried to use an empty list or an empty dictionary as a default argument, see, e. g., “Least Astonishment” and the Mutable Default Argument).
Just a moment ago, I told you that the two functions is_letter_A and is_lette_B are not identical, even though their code is. This can be seen by looking at their __code__ attribute (we are taking our latest version of make_is_letter here).
is_letter_A = make_is_letter({'_'})
is_letter_B = make_is_letter({'_', '-', '?'})
print(id(is_letter_A.__code__), id(is_letter_B.__code__))But if the code of two functions is the same, what can be different, then? One answer is that the default arguments might differ. While the argument names (like c, specials) are stored as part of the code, the default values are not. They are part of the function object, not its code.
print(is_letter_A.__defaults__) # prints ({'_'},)
print(is_letter_B.__defaults__) # prints ({'?', '-', '_'},)You will find this trick of using default arguments every once in a while in the open. In most cases, though, the name and value of the default argument are chosen to be the same, like so:
def is_letter(c, special_chars=special_chars):
return 'A' <= c <= 'Z' or 'a' <= c <= 'z' or c in special_charsWhat this code does, really, is capturing what special_chars currently refers to, and putting that into the function. Here is another example, where you actually need this technique:
multipliers = []
for i in range(11):
def _mul(x, i=i):
return x*i
multipliers.append(_mul)
print( multipliers[2](123) ) # prints 246Granted, the example code is sort of boring and stupid, but it nicely illustrates the idea of capturing what the variable i is currently referring to. What happens, if you define _mul just like below?
def _mul(x):
return x*iIn this case, the i in all multipliers refers to the same object/value, which is 10 at the time we call multipliers[2](123). Hence, it will print 1230. Be careful, though, when working with mutable objects such as lists, as this might not work then (see, once again, “Least Astonishment” and the Mutable Default Argument).
The Automatic Solution
Closing in on Closures.
Sure, the default argument trick is neat. But as the programs grow larger, I might end up having to specify a lot of default arguments all the time. To avoid having to specify more than one default argument, I could just give a copy of the local namespace, and then refer to that from inside the function. Or in code:
def make_is_letter(special_chars: set):
def is_letter(c, parents_locals=locals()):
return 'A' <= c <= 'Z' or 'a' <= c <= 'z' or c in parents_locals['special_chars']
return is_letterEven though this works, it certainly wouldn’t win a beauty contest. But it captures pretty well what Python is actually doing behind the scenes!
A nested function that captures (some of) the local variables of its parent function is called a closure. If you just take the code of the function, i. e.:
def is_letter(c):
return 'A' <= c <= 'Z' or 'a' <= c <= 'z' or c in special_charsthere is an unresolved (open) reference to special_chars in this code. Before Python can execute the code, it needs to close the open references in the code. If we build a closure of a function, we combine the function with a dictionary that gives a value for each open reference in the code.
Python builds closures in two steps. The code of a function has a list of free (open) variables, which you can access as f.__code__.co_freevars. Whenever you create a new function with def, Python finds a value for each of these free/open variables in the code, and then stores these values in a field called __closure__ (packed as a Cell, but we’ll cover that later).
def make_is_letter(special_chars: set):
def is_letter(c):
return 'A' <= c <= 'Z' or 'a' <= c <= 'z' or c in special_chars
return is_letter
is_letter_A = make_is_letter({'_', '-', '?'})
print(is_letter_A.__code__.co_freevars)
print(is_letter_A.__closure__[0].cell_contents)If you fancy, you can actually manipulate the captured variable (even though the adults will probably tell you not to do that):
is_letter_A.__closure__[0].cell_contents.add('!')When you look closely at closures, you will see that Python is smart enough to figure out which variables are really needed in a function. Hence, it will not capture the entire local namespace of the surrounding function scope, but only what is really needed.
By the way: another way to inspect the closure of a function is, of course, through the inspect module:
import inspect
print(inspect.getclosurevars(is_letter_A))Functions Are Objects
More than Code.
Traditionally, we tend to think of a function in the context of code. A function, that is a special part of your code, a part you can jump to, and then return from. In Python, however, functions are first-class objects: a function is not just a piece of code, but truly a full (data) object, and thus something you can store in a variable, or pass on as an argument, for instance. The code of a function is, of course, an important part of it. But there is other data stored along with it, such as values for its default arguments, or the variables needed to form the closure. There is thus a clear distinction between a function, and its code.
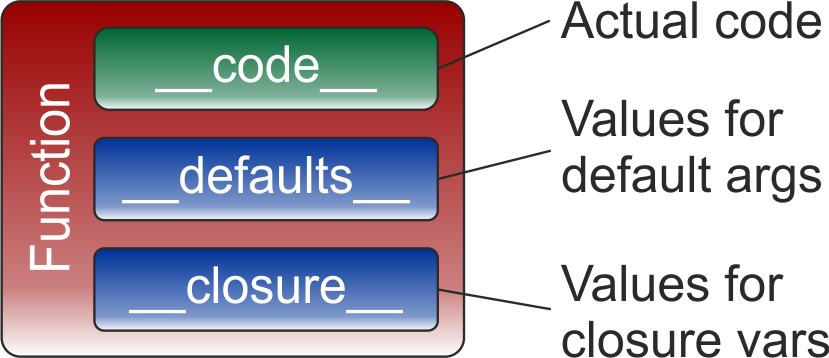
Whenever Python encounters a def statement, it creates a new function, that is a new function object. This does not mean that the function’s source code is recompiled. The code part of a function (which is an object, too), is created by the compiler only once, and then shared by all functions, which are created by the same def statement. But each time, Python will recompute values for the default parameters, and the closure variables. Naturally, you will only ever take notice of that if your function definition is executed more than once during a program’s execution; hence, if the function definition is inside a loop, or another (repeatedly called) function.
Conclusion
We have covered a lot of ground in today’s article. Something as seemingly innocuous as nesting functions quickly led to cases, where we had to think about keeping local variables alive. The technique used for this are closures. Doing this correctly is far from trivial, though, and there are some crucial issues we have not covered yet.
One of the take aways is that a function object in Python is not just the code. It has additional fields to capture the values of default arguments, and the surrounding scope, among others. If we combine the code of a function in this way with values for each of its (open/free) variables, it is called a closure. This makes function objects incredibly powerful.